Is there a difference between the Planchon & Darboux and Wang and Liu depression filling algorithms? Other than speed?
An answer to this question on the GIS Stack Exchange.
Question
Can anyone tell me, based on actual analytical experience, if there is a difference between these two depression filling algorithms, other than the speed at which they process and fill depressions (sinks) in DEMs?
A fast, simple and versatile algorithm to fill the depressions of digital elevation models
Olivier Planchon, Frederic Darboux
and
Wang and Liu
Thanks.
Answer
At an algorithmic level, the two algorithms will produce the same results.
Why might you be getting differences?
Data Representation
If one of your algorithms uses float (32-bit) and another uses double (64-bit), you should not expect them to produce the same result. Similarly, some implementations represent floating-point values uses integer data types, which may also result in differences.
Drainage Enforcement
However, both algorithms will produce flat areas which will not drain if a localized method is used to determine flow directions.
Planchon and Darboux address this by adding a small increment to the height of the flat area to enforce drainage. As discussed in Barnes et al. (2014)'s paper "An efficient assignment of drainage direction over flat surfaces in raster digital elevation models" the addition of this increment can actually cause drainage outside of a flat area to be unnaturally rerouted if the increment is too large. A solution is to use, e.g., the nextafter function.
Other Thoughts
Wang and Liu (2006) is a variant of the Priority-Flood algorithm, as discussed in my paper "Priority-flood: An optimal depression-filling and watershed-labeling algorithm for digital elevation models".
Priority-Flood has time complexities for both integer and floating-point data. In my paper, I noted that avoiding placing cells in the priority queue was a good way to increase the algorithm's performance. Other authors such as Zhou et al. (2016) and Wei et al. (2018) have used this idea to further increase the algorithm's efficiency. Source code for all these algorithms is available here.
With this in mind, the Planchon and Darboux (2001) algorithm is a story of a place where science failed. While Priority-Flood works in O(N) time on integer data and O(N log N) time on floating-point data, P&D works in O(N1.5) time. This translates into a huge performance difference that grows exponentially with the size of the DEM:
[ ]1
]1
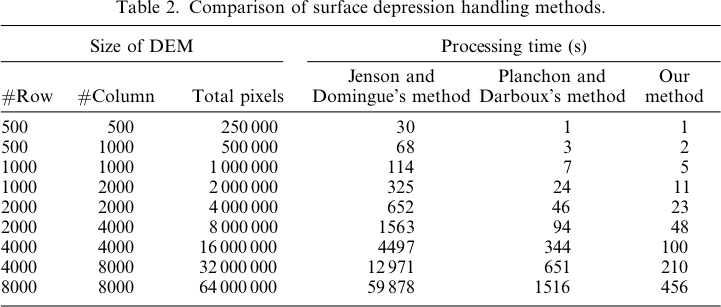{kind=link}
By 2001, Ehlschlaeger, Vincent, Soille, Beucher, Meyer, and Gratin had collectively published five papers detailing the Priority-Flood algorithm. Planchon and Darboux, and their reviewers, missed all of this and invented an algorithm which was orders of magnitude slower. It's now 2018 and we're still building better algorithms, but P&D is still being used. I think that's unfortunate.